Orchestration Archetypes: Mastering Task Definitions, Tasks, and Services
Building at scale requires more than just running containers. Explore the foundational hierarchy of container orchestration understanding the relationship between immutable Task Definitions, ephemeral Tasks, and the self-healing intelligence of Services
In a modern distributed environment, managing the lifecycle of a container manually is an operational bottleneck. To build resilient applications, we must move beyond the "single container" mindset and embrace the hierarchical architecture of Container Orchestration.
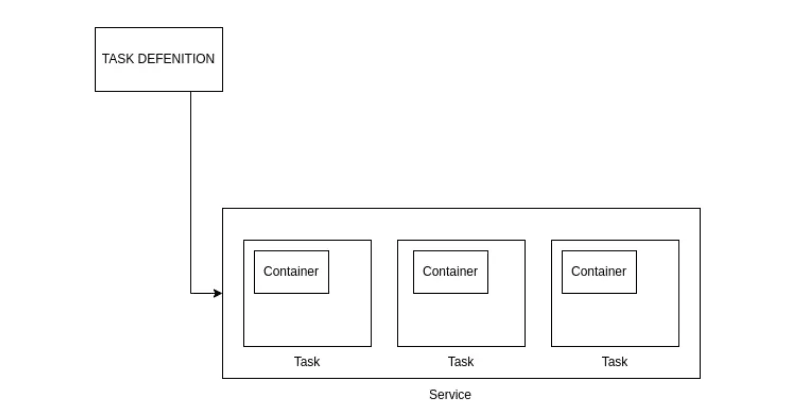
In the context of platforms like Amazon ECS, this hierarchy is built on three pillars: Task Definitions, Tasks, and Services. Understanding the flow between these components is essential for architecting self-healing, scalable systems.
Phase 1: The Task Definition (The Immutable Blueprint)
Think of a Task Definition as the source of truth for your infrastructure. It is an immutable JSON-based template that specifies exactly how a container should be instantiated.
A Task Definition encapsulates several critical parameters:
- Image URI: The specific version of the code from your registry.
- Compute Allocation: Hard limits for CPU and Memory (RAM).
- Environment Injection: Security credentials, API keys, and environment variables.
- Networking Isolation: Definition of bridge, host, or awsvpc network modes.
- Volume Mounts: Mapping of persistent or ephemeral storage.
Because they are versioned (Revision 1, 2, 3...), they allow for seamless rollbacks and predictable deployments across development and production environments.
Phase 2: The Task (The Ephemeral Execution Unit)
When you instantiate a Task Definition, you create a Task. In technical terms, a Task is the running instance of your container(s) on a compute node.
However, a Task is inherently ephemeral. By design, a Task runs as long as its internal process remains active. If the program finished its work or the container crashes due to a resource breach, the Task enters a STOPPED state. Tasks do not possess "self-healing" properties on their own; once they stop, they stay stopped.
Phase 3: The Service (The Self-Healing Orchestrator)
To achieve high availability, we overlay a Service on top of our Tasks. The Service acts as a persistent manager that ensures your "Desired State" is always maintained.
Core Responsibilities of a Service:
- Desired State Management: If you specify a replica count of 3, the Service monitors the cluster. If one Task fails or an EC2 instance goes down, the Service instantly identifies the discrepancy and spawns a replacement Task.
- Scalability: Services scale the replica count dynamically based on workload demands (CPU/Memory utilization).
- Load Balancer Integration: Services automatically register new Tasks with Target Groups, ensuring that traffic only flows to "Healthy" containers.
Advanced Pattern: The Multi-Container Task
An often-underutilized advantage of this architecture is the ability to run Multiple Containers within a single Task. This is the foundation of the Sidecar Pattern.
By grouping containers in a single Task, they share the same network namespace (localhost) and lifecycle. This allows you to run a primary application container alongside specialized helper containers—such as a logging agent, a proxy (like Envoy), or a security scanner—providing a modular and advanced containerized environment.
Conclusion
Orchestration is the bridge between a "working script" and a "production application." By decoupling your blueprint (Task Definition) from your execution (Task) and managing them through a resilient supervisor (Service), you move from manual management to automated, self-healing infrastructure.
Happy Orchestrating! 🚀🛡️
Fuel the Architecture
If this deep dive helped you build something better, consider fueling my next late-night coding session.
Newsletter Updates
Join 1,000+ engineers receiving weekly insights into AI, cloud architecture, and technical guides.